아마존의 알렉사 과학자들은 더 큰 인공지능이 항상 더 좋은 것은 아니라는 것을 보여줍니다.
아마존의 알렉사 과학자들은 인공지능의 크기와 질이 항상 비례하지 않는다는 것을 보여줍니다.
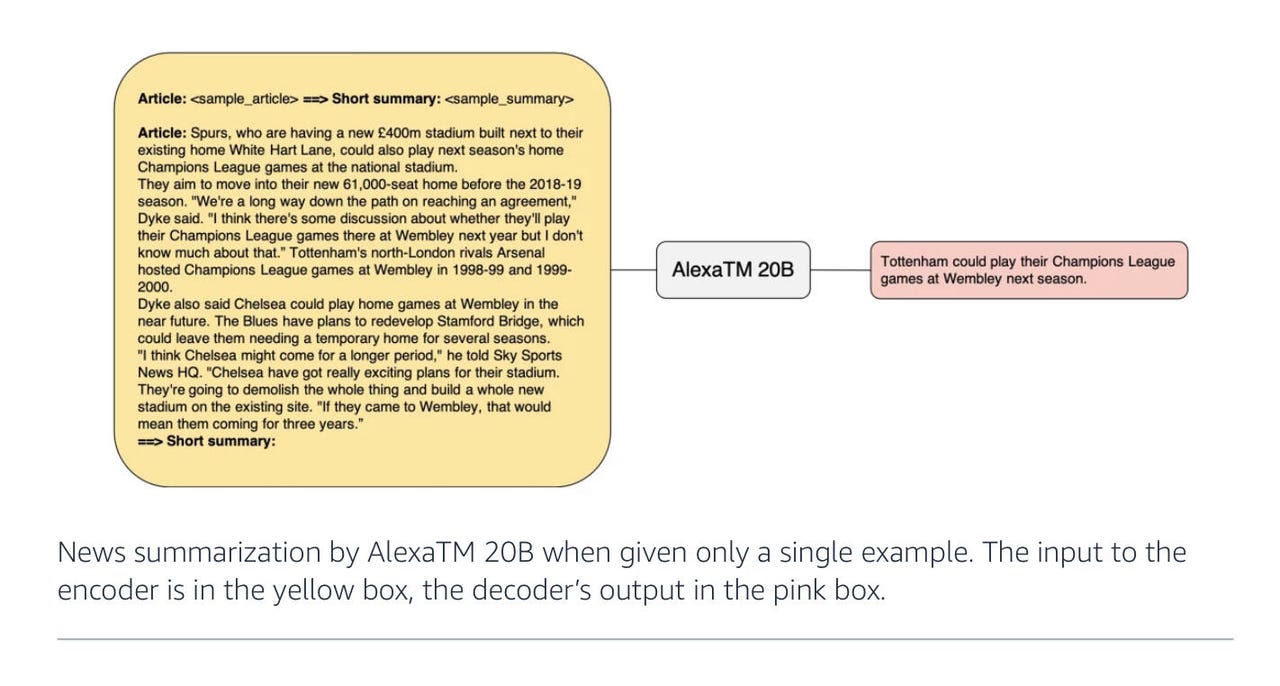
기사의 중심 포인트를 설명하는 단어들의 압축된 시퀀스로 모든 단어를 줄이는 것은 딥러닝에서의 벤치마크 작업 중 하나입니다. 아마존의 Alexa AI 과학자들은 이 작업에서 DeepMind, Google, Meta, OpenAI 등의 규모가 훨씬 큰 컴퓨터 프로그램들의 노력을 능가할 수 있다고 말하고 있습니다. 이 작업은 에너지 사용과 탄소 발자국 효율에 영향을 미칩니다.
요즘 기계 학습에서는 두 가지 주요한 연구 분야가 강세를 보입니다: 프로그램을 더 일반화된 방식으로 만드는 것(어떤 잠재적인 작업이든 처리할 수 있도록)과 그 크기를 더 크게 만드는 것입니다.
파라미터 또는 “가중치”로 측정한 가장 큰 신경망은 5000억 개의 가중치를 가지고 있습니다. Google의 Pathways Language Model 또는 PaLM, Nvidia와 Microsoft의 Megatron-Turing NLG 530B는 각각 5400억과 5300억 개의 파라미터를 가진 가장 큰 신경망 중 하나입니다. 일반적으로 프로그램이 가진 파라미터가 많을수록 훈련에 필요한 컴퓨팅 파워가 많아지고, 예측을 위해 실행하는 데에도 많은 컴퓨팅 파워가 필요합니다. 이를 추론이라고 합니다.
인공지능
- 알아야 할 7가지 고급 ChatGPT 프롬프트 작성 팁
- 2023년 최고의 ChatGPT 플러그인 10가지 (그리고 그들을 최대한 활용하는 방법)
- 업무용으로 많은 AI 도구를 테스트했습니다. 지금까지 제가 가장 좋아하는 5가지입니다.
- 인간인가 봇인가? 이 튜링 테스트 게임은 당신의 AI 감지 능력을 시험합니다.
AI의 전문가들은 파라미터 수가 분명히 늘어나는 경향이 있다고 주장하며, 트리리온 개 이상의 파라미터를 가지는 모델들이 미래에는 나올 것이라고 믿습니다. 100조 개의 신경 연결점인 시냅스 개수로 알려진 수치는 종종 일종의 기준 역할을 하기 때문에 특별한 의미를 가지고 있습니다.
또한: Nvidia는 Megatron-Turing의 규모 주장을 명확히 합니다
동시에 가능한 일반적인 딥러닝 신경망을 만들기 위한 열정도 존재합니다. 지난 40년간 기계 학습의 역사에서는 이미지 인식이나 음성 인식과 같은 작업에 특화된 프로그램들이 있었습니다. 그러나 최근들어 DeepMind의 Perceiver AR, 그리고 Gato라고 불리는 또 다른 DeepMind 프로그램과 같이 일반화 가능한 프로그램들이 점점 더 많아지고 있습니다. 이 프로그램들은 다양한 작업을 해결할 수 있는 “일반적인 에이전트”라고 불리기도 합니다.
Richard Sutton과 같은 기계 학습의 선구자들의 관측에 따르면 “계산을 활용하는 더 일반적인 모델이 종종 보다 전문화된 도메인 특화 접근법을 앞서는 경향이 있었다”고 말하고 있습니다.
또한: DeepMind의 ‘Gato’는 중간 정도의 성능이지만, 왜 만들었을까요?
그러나 때로는 거대하고 일반적인 것보다는 경제적이고 다소 특화된 딥러닝 결과가 나오기도 합니다.
이러한 거대한 프로그램과 일반화된 프로그램들과는 대조적으로 아마존의 연구진들은 지난 주에 200억 개의 파라미터만을 가진 신경망 프로그램을 발표했는데, 이 프로그램은 몇 가지 중요한 딥러닝 벤치마크 작업(예: 기사 요약)에서 가장 크고 가장 일반적인 모델들보다 뛰어난 성능을 보여줍니다.
지난 주 arXiv에 게시된 “AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model”라는 논문에서 아마존 Alexa AI의 저자인 Saleh Soltan과 동료들은 200억 개의 파라미터가 기사를 몇 문장으로 요약하는 등의 특정 작업에서 PaLM과 같은 더 큰 모델보다 뛰어난 성능을 보여주는 것으로 나타냈습니다.
이 논문과 함께 Soltan은 해당 주제에 대한 블로그 글도 작성했습니다.
아마존의 연구는 최근의 문헌 연구에서 크기를 늘리는 대안을 찾기 위한 광범위한 추세의 일부입니다. 페이스북과 인스타그램 소유주인 Meta에서 지난 주에 발표한 “Few-shot Learning with Retrieval Augmented Language Models”라는 논문이 좋은 예입니다. 이 논문에서는 110억 개의 파라미터만 가진 Atlas라는 언어 모델을 소개하고 있으며, 단 64개의 예시 데이터 포인트를 사용하여 훈련되었습니다.
AlexaTM 20B와 마찬가지로, 저자들은 Atlas 프로그램이 64개의 예제만으로도 PaLM을 큰 폭으로 앞서고 있다고 쓰고 있다. Atlas의 핵심은 미리 훈련된 언어 모델과 인터넷 소스에서 정보를 검색하는 능력을 결합하는 것이다. 마치 답을 얻기 위해 친구에게 전화를 거는 것과 같다.
또한: DeepMind의 Perceiver AR: AI 효율성을 향한 한 단계
AlexaTM 20B의 경우, 아마존 저자들은 세 가지 조정을 통해 점수를 달성한다.
아마존 2022 AlexTM 20B 다이어그램
첫 번째 흥미로운 조정은 최근의 거대한 언어 모델에서 제외된 요소 중 하나를 복원하는 것이다. AlexaTM 20B의 기초는 PaLM과 GPT-3 등과 같은 Transformer 인코더-디코더와 같다. 이 접근 방식은 2017년 구글 과학자인 Ashish Vaswani와 동료들에 의해 개척되었다.
Transformer는 “자기 주의”라는 단위를 사용하여 각 단어가 다른 단어의 맥락에서 어떻게 찾을 수 있는지에 대한 확률 점수를 생성한다. 이 점수는 의미 있는 텍스트 블록을 형성하기 위해 단어를 예측할 때 빈 칸을 채우는 데 사용된다.
AlexaTM 20B의 경우, Soltan과 동료들은 PaLM과 GPT-3 및 원래 Transformer의 거대한 자손들과의 중요한 차이를 보인다. 이러한 최근 모델들은 인코더 (입력 데이터를 숨겨진 상태로 매핑하여 답변으로 디코딩하는 것)라고 불리는 것을 없앴다. 대신, PaLM과 GPT-3은 입력과 디코더를 병합하여 “디코더 전용” 모델로 만든다.
Alexa 팀은 인코더를 프로그램에 다시 추가한다. 그들의 주장은 두 요소를 모두 갖는 것이 “노이즈 제거”라고 불리는 작업에서 정확도를 향상시키는 데 도움이 된다는 것이다.
디코더 전용 모델에서는 예측된 텍스트의 조건부 확률은 한 방향으로만 진행된다. 다음 답변은 이전에 나온 내용에만 기반한다. 그러나 전체 인코더-디코더 버전에서는 모델이 둘 다 평가하고 있으며, 주어진 단어의 이전 내용과 이후 내용에 대한 확률을 평가한다. 이는 문장에서 다음 요소만 생성하는 것뿐만 아니라 다른 언어로의 번역과 같은 단어 대 단어 비교와 같은 작업에 더 적합하다.
아마존 2022 AlexTM 20B 디코더 전용 모델
또한: Meta의 거대한 다국어 번역 작품은 그리스어, 아르메니아어, 오로모어에서 여전히 막힌다
저자들의 말대로, “AlexaTM 20B는 노이즈 제거 모드에서 제로샷 설정에서 82.63%의 새로운 최고 성능을 달성한다. 노이즈 제거 모드에서 더 잘 수행되는 이 작업의 주된 이유는 인코더와 디코더 모두에서 입력이 반복되어 최상의 답변을 찾기 위해 인코더와 디코더를 모두 사용할 수 있다는 것이다.”
저자들이 추가한 두 번째 사항은 “인과적 언어 모델링”이라고 불리는 모델을 훈련시키는 것이다. CLM은 GPT-3 및 기타 디코더 전용 Transformers에서 사용되는 작업이다. 이 작업에서 각 단어는 앞에 나온 단어에만 의존하는 순차적인 일방향 종속성으로 표현된다. 이는 초기 프롬프트를 기반으로 문장을 생성하는 데 사용된다.
저자들은 AlexaTM 20B를 노이즈 제거 작업과 인과적 작업을 혼합하여 훈련시킨다. 노이즈 제거 작업은 훈련 활동의 80%를 차지하고 인과 모델링은 나머지 20%를 차지한다.
인과적 모델링을 추가하는 장점은 GPT-3과 유사하게 “문맥 학습”에 도움이 된다는 것이다. 문맥 학습은 제로샷 또는 페우샷 학습을 수행할 수 있는 모든 모델을 포괄하는 넓은 범주이다. 즉, 프로그램에는 도메인별 지식이 없다. 예제 프롬프트를 제시하면 프로그램이 질문 유형과 일치하는 예측을 수행한다.
그 혼합 훈련 체제 때문에 AlexTM 20B는 문장을 재구성하는 데 능숙하지만, 노이즈 제거 작업 외에도 “인-컨텍스트 학습”이 가능한 “첫 번째 다국어 seq2seq [sequence to sequence] 모델”이라고 저자들은 쓴다. 다시 말해, 그것은 하이브리드 프로그램이다.
Soltan과 동료들이 추가한 세 번째 흥미로운 조정은 훈련 중에 프로그램에 입력되는 데이터 포인트의 크기를 크게 증가시키는 것이다. 훈련 과정에서 1조 개의 “토큰”이라는 개별 데이터 조각을 입력한다. 이는 GPT-3이 받는 것보다 3배 이상이다. 이 경우 훈련 데이터 세트는 Wikipedia 항목과 Google의 Linting Xue와 동료들이 작년에 소개한 mC4라는 데이터 세트로 구성된다. 이는 Common Crawl 웹 스크래핑 데이터 소스에서 가져온 101개 언어의 자연 언어 텍스트를 기반으로 한다.
또한: Sentient? Google LaMDA는 일반적인 챗봇 같아 보인다
아마존 작업의 핵심 요소 중 하나는 매우 많은 양의 입력 훈련 데이터를 사용하는 것이다. Soltan과 팀은 이를 기반으로 하여 아래에 출판된 OpenAI의 Jordan Hoffman과 동료들의 관찰을 따라갔다. 그들은 지난 3월에 발표된 “컴퓨팅 최적의 대형 언어 모델 훈련”이라는 논문에서 이 관찰을 기술했다.
그 논문에서 Hoffman과 동료들은 “현재 대형 언어 모델은 훈련이 더 필요하며, 최근 언어 모델의 확장과 훈련 데이터 양을 일정하게 유지하려는 초점에 따른 결과”라고 결론지었다. 작성자들은 다양한 크기의 언어 모델을 사용하여 입력 토큰의 양에 따라 모두 테스트한 결과, “컴퓨팅 최적의 훈련을 위해서는 모델의 크기와 훈련 토큰의 양을 동일하게 확장해야 한다”고 결론지었다.
따라서, AlexaTM 20B는 단지 절약적일 뿐만 아니라, 더 많은 훈련 데이터로 균형 잡힌 퍼포먼스를 보여줄 수 있는지를 증명하기 위한 것이다.
ENBLE 추천
어떤 아마존 에코를 구매해야 할까요? 당신의 요구에 가장 적합한 Alexa 기기를 선택하는 방법
아마존은 이제 전체 에코 기기 군단을 보유하고 있다. 일부는 당신을 듣고, 일부는 당신을 보기도 한다. 어떤 것을 선택해야 할까요? 우리가 도와드리겠습니다.
또한, 작성자들은 입력의 대부분을 자연스러운 회화 텍스트로 구성하여 대문자와 문장 부호를 생략하는 데 신경을 쓴다. 이는 Alexa 설정에서 중요한 역할을 한다. “우리는 내부 사용 사례를 충족시키기 위해 말하기보다 쓰기 위주의 텍스트를 포함시켰다”고 작성자들은 설명한다.
Alexa AI 팀의 일부 기술은 Alexa 제품에 사용되지만, 아마존은 이메일로 ENBLE에 말했듯이 그룹이 “전망있는 연구”도 수행한다. 아마존은 AlexaTM 20B 모델이 현재는 주로 연구 프로젝트인 것으로 설명했다.
아마존은 덧붙였다. “이 모델이 나중에 제품에 배포될 수도 있지만, 가드레일이 있는 수정 버전만을 사용하여 Alexa 기능과 제품을 개발할 것”이라고 말했다.
또한: Google의 대규모 언어 번역 작업은 어디에서 실수하는지를 확인했다
작성자들은 AlexaTM 20B 모델을 “128 개의 [Nvidia] A100 GPU에서 120 일 동안 훈련하였으며, 누적 배치 크기가 200 만 토큰(1 조 토큰 업데이트의 총합)인 500k 개 업데이트를 수행했다”고 기술했다.
이는 아마도 많은 양이라고 생각될 수 있지만, 구글이 네 번째 세대 TPU 팟인 2개의 PaLM에서 훈련한 PaLM보다는 적은 양이다. 각 팟은 3,072 개의 TPU 칩이 부착된 768 개의 호스트 컴퓨터에 연결되어 있다.
구글의 Aakanksha Chowdhery와 팀은 4월에 언급한 대로, 그것은 “지금까지 기술된 가장 큰 TPU 구성”이었다.
결과는 특정 테스트 결과에서 설명되었다. Soltan과 팀은 특정 작업에 대한 성공에 특히 강조를 두었다. 예를 들어, Soltan과 팀은 “AlexaTM 20B가 요약 작업에서 현재까지 가장 큰 밀집 디코더 전용 모델인 PaLM 540B와 1회 훈련 및 파인튜닝 설정에서 동등하거나 더 나은 성능을 보인다”고 관찰했다. 이는 특히 MLSum이라고 하는 단락 요약 작업에서 독일어, 스페인어, 프랑스어에서 AlexaTM 20B가 PaLM을 압도했음을 의미한다.
2020년에 프랑스 국립과학연구소에서 소개된 MLSum 벤치마크 테스트는 신문 기사 150만 개로 구성되어 있다. 이 작업은 언어 모델이 전체 기사에 기술된 아이디어를 표현하는 몇 개의 문장을 출력하는 것을 목표로 한다. 이는 수백 단어를 수십 개의 단어로 축소하는 것을 필요로 한다.
아마존
- 구형 Fire 태블릿을 Echo Show로 변환하는 방법
- 아마존 기기를 아마존 기프트 카드로 교환하는 방법. 여기에는 어떤 것이 있나요
- 최고의 아마존 태블릿: Fire로 놀아보세요
- 아마존 킨들 스크라이브 리뷰: 7 개월 후, 완벽에 아주 가까워집니다
영어로 수행된 네 번째 테스트인 XSum에서 AlexaTM 20B 모델은 2위를 차지했으며, AlexaTM 20B보다 크고 PaLM의 5400억 매개변수 버전보다 작은 PaLM 버전을 이기었다.
요약에 뛰어난 성능을 보이지만, AlexTM 20B는 일부 다른 작업에서 실패한다. 예를 들어, “추론” 데이터 세트(예: MultiArith)와 “사고 과정” 추론 작업(자연어로 작성된 매우 간단한 산술 문제)에서는 GPT-3와 같은 훨씬 더 큰 모델이 달성한 것보다 훨씬 뒤떨어진다.
또한: Graphcore의 CEO는 인공지능의 미래는 소프트웨어 이야기라고 말합니다
Soltan과 팀은 다음 단계에 대한 문제의 힌트로 프로그램에 제공되는 단서를 의미합니다. “AlexaTM 20B은 비슷한 크기의 모델보다 약간 더 나은 성능을 발휘하지만 GPT3 175B와 같은 훨씬 큰 모델에서 나타나는 이러한 특별한 프롬프트의 이득을 관찰하지 못했습니다.”
“결과는 모델 파라미터의 확장이 ‘추론’ 작업에서 잘 수행되는 데 중요하다는 것을 나타냅니다. 이는 이전에 Instruct-GPT3 모델을 사용하여 디코더 전용 구조에서 시연되었던 것입니다.”
요약과 같은 성공적인 작업에 초점을 맞추면 Soltan과 팀이 도달한 주요 결론은 프로그램을 훈련시키기 위해 노이즈 제거 및 인과 언어 모델링의 목표를 모두 사용하는 혼합 접근법이 더 효율적이라는 것입니다.
“이는 혼합 사전 훈련이 추가적인 멀티태스크 훈련이 아니라 강력한 seq2seq 기반 대규모 언어 모델(Large-scale Language Models, LLM)을 훈련시키는 핵심이라는 것을 시사합니다,” 그들은 씁니다.
크기에 대한 원래 질문으로 돌아가면, 많은 맥락에서 알려진 대로 점점 커지는 인공지능 프로그램의 에너지 사용은 인공지능 실천 내에서 윤리적인 문제입니다. 저자들은 더 효율적인 접근법의 관련성에 대해 강력한 주장을 제시합니다.
또한: 인공지능의 윤리: 인공지능의 장점과 위험
AlexaTM 20B는 “GPT3 175B와 같은 모델보다 훨씬 작지만 다양한 작업에서 비슷하거나 더 나은 성능을 발휘합니다,” 그들은 씁니다. “따라서 AlexaTM 20B를 추론에 사용하는 것의 지속적인 환경 영향은 더 큰 모델보다 훨씬 적습니다(대략적으로 8.7배 낮음).”
그들은 덧붙입니다, “따라서 시간이 지남에 따라 AlexaTM 20B의 탄소 발자국도 낮아집니다.”
저자들은 상대적인 탄소 발자국을 보여주는 통계 표를 제공하며, 숫자에서 큰 차이가 있습니다.
이는 탄소 발자국에 대한 Amazon 2022 AlexTM 20B 비교 차트입니다.
탄소 발자국의 이 표는 아마도 모든 이들에게서 가장 흥미로운 측면입니다. 더 깊은 학습 연구는 주어진 접근법의 에너지 효율성을 보여주기 위해 환경 평가의 점수를 제시하려 할 것으로 보입니다. 이는 세계적으로 “ESG”라는 것, 즉 환경, 사회, 거버넌스 요소에 대한 초점이 점점 높아지는 것과 일치합니다.
이는 어떤 면에서 생태 친화적인 것이 주류 인공지능 연구의 목표의 일부가 되었다는 것을 의미할 수 있습니다.
또한: 60초 안에 알아보는 인공지능