메타(Meta)의 AI 전문가 LeCun 오늘날 대부분의 AI 접근 방식은 진정한 지능으로 이어지지 않을 것이다.
Most AI approaches today will not lead to true intelligence, according to LeCun, an AI expert at Meta.

“AI 시스템은 추론할 수 있어야 한다고 생각합니다,” 말하는 메타의 주요 AI 과학자인 야안 르쿤은 말합니다. 트랜스포머와 같은 오늘날 인기 있는 AI 접근법들은 그가 이 분야에서의 개척적인 작업 위에 세워진 많은 접근법들이지만 충분하지 않을 것입니다. “우리는 이 사다리를 만들었지만, 우리는 달로 가려고 하는데 이 사다리로는 갈 수 없다는 것을 알아야 합니다,” 르쿤은 말합니다.
(기사는 Gary Marcus와 Jürgen Schmidhuber의 반론이 문맥에 포함되어 업데이트되었습니다.)
페이스북, 인스타그램, 그리고 왓츠앱의 소유주인 Meta의 주요 AI 과학자인 야안 르쿤은 그의 분야에서 많은 사람들을 화나게 할 것으로 예상됩니다.
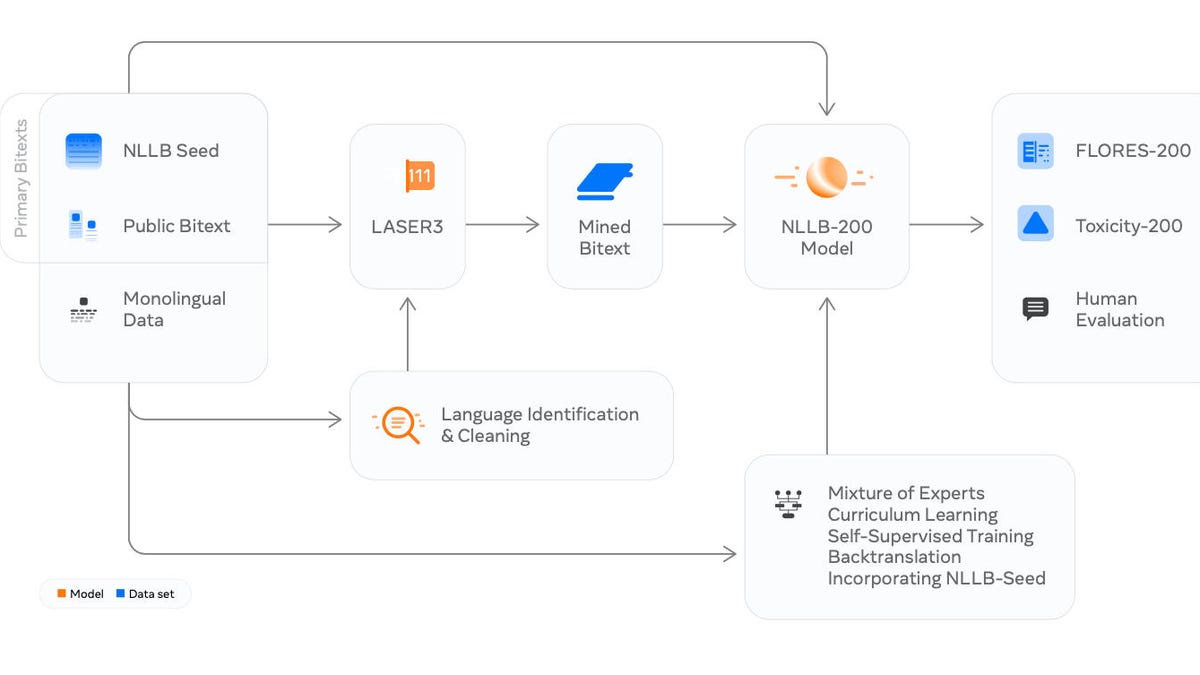
Open Review 서버에 6월에 게시된 논문에서, 르쿤은 기계에서 인간 수준의 지능을 달성하기 위한 약속이 있는 접근법에 대해 포괄적인 개요를 제시했습니다.
논문에서는 명시적으로는 아니지만, 대부분의 오늘날의 대형 AI 프로젝트들이 인간 수준의 목표를 달성할 수 없을 것이라는 주장이 함축되어 있습니다.
- AI 비평가인 게리 마르커스(Gary Marcus)는 ‘메타’의 르쿤(...
- Meta의 저크버그 ‘AI는 아마도 우리 시대의 가장 중요한 기초 기...
- Meta가 첫 번째 맞춤형 AI 칩을 공개합니다.
이번 달 ENBLE와의 Zoom을 통한 토론에서, 르쿤은 현재 딥러닝 분야에서 가장 성공적인 연구 방향들을 큰 회의론적인 시각으로 바라보고 있다는 것을 분명히 했습니다.
“저는 그들이 필요하지만 충분하지 않다고 생각합니다,” Turing Award 수상자인 그는 동료들의 연구에 대해 ENBLE에게 이렇게 말했습니다.
이에는 GPT-3와 같은 대형 언어 모델들도 포함됩니다. 르쿤은 이를 설명할 때, 트랜스포머의 추종자들은 “우리는 모든 것을 토큰화하고 이산적인 예측을 수행하기 위해 거대한 모델을 훈련시키며, 그래서 어떻게든 AI가 이것에서 나타날 것이라고 믿습니다.”
그는 말합니다. “그들은 틀리지 않습니다. 그것이 미래의 지능 시스템 구성 요소의 일부일 수도 있지만, 저는 그것이 필수적인 부분들이 빠져 있다고 생각합니다.”
또한: 메타의 AI 거장 르쿤이 깊은 학습의 에너지 전선을 탐구합니다
이는 실용적인 기법인 합성곱 신경망의 사용을 완벽하게 활용한 학자로부터 나오는 성과로 보이는 것에 대한 놀라운 비판입니다.
르쿤은 이 분야의 다른 많은 성공적인 영역들에 결함과 한계를 보고 있습니다.
강화 학습만으로도 충분하지 않다고 그는 주장합니다. AlphaZero 프로그램을 개발한 DeepMind의 David Silver와 같은 연구자들은 “매우 행동 중심적인” 프로그램에 초점을 맞추고 있다는 르쿤은 관찰을 통해 배우는 것이 대부분의 학습이라고 말합니다.
하지만 수십 년의 성과를 통해, 62세인 르쿤은 많은 사람들이 서두르고 있는 막다른 길에 대해 대면해야 하며, 그의 분야를 그가 생각하는 방향으로 이끄는 것을 시도해야 한다는 긴급함을 표현합니다.
“우리는 우리의 지능적인 기계가 고양이만큼의 상식을 가지고 있다는 정도에 이르지 않았습니다,” 르쿤은 말합니다. “그래서, 왜 우리가 거기서 시작하지 않을까요?”
그는 비디오의 다음 프레임을 예측하는 것과 같은 생성 네트워크를 사용하는 믿음을 버렸습니다. “완전한 실패였습니다,” 그는 말합니다.
르쿤은 “확률론적 종교인”이라고 부르는 사람들도 비판합니다. “머신 러닝을 설명하기 위해 확률론적 이론만 사용할 수 있다고 생각하는 사람들,” 그는 말합니다.
그에 따르면 순수한 통계적 접근은 해결하기 어렵습니다. “전적으로 확률론적인 세계 모델을 요구하는 것은 너무 많은 것을 요구하는 것입니다. 우리는 그것을 어떻게 할지 모릅니다.”
학계뿐만 아니라 산업용 AI도 심층적인 재고가 필요하다고 르쿤은 주장합니다. Wayve와 같은 스타트업을 포함한 자율주행 자동차 분야는 “데이터를 던지면서” 대형 신경망에서 “거의 모든 것을 배울 수 있다고” 생각하기 때문에 “너무 낙관적입니다,” 그는 말합니다.
그는 “ADAS”라고 부르는 자율주행을 위한 고급 운전자 지원 시스템 용어에 대해 “상식 없이 레벨 5의 자율차가 가능할 수 있다고 생각한다. 하지만 그걸 구현하기 위해서는 엄청난 엔지니어링이 필요할 것”이라고 말했다.
그는 이러한 과도한 엔지니어링이 딥러닝에 의해 사용되지 않게 된 모든 컴퓨터 비전 프로그램처럼 부서지기 쉽고 취약한 자율주행 기술이 될 것이라고 믿는다.
“결국, 세상이 어떻게 돌아가는지 더 잘 이해하는 시스템을 포함한 더욱 만족스럽고 가능성 있는 해결책이 있을 것”이라고 그는 말했다.
이와 함께 LeCun은 NYU 교수인 Gary Marcus와 Jürgen Schmidhuber, Dalle Molle 인공지능 연구소 공동 소장과 같은 가장 큰 비판자들에 대해 일침을 가했다. “그는 인공지능에 아무런 기여를 한 적이 없다”며 전자에 대해 말했고, “기발한 이론을 제시하는 것은 매우 쉽다”며 후자에 대해 말했다.
그러나 LeCun이 제기한 가장 중요한 점은 모든 AI가 직면하는 특정한 근본적인 문제들, 특히 정보를 어떻게 측정할 것인지에 대한 문제들이라는 것이다.
“우리는 이 사다리를 만들었지만, 우리는 달로 가고 싶다. 그러나 이 사다리로는 달에 도달할 수 없다”고 LeCun은 기본 개념에 대한 재고를 일깨우기를 원하는 바를 말했다. “기본적으로, 여기에서 쓰는 것은 로켓을 만들어야 한다는 것이다. 로켓을 어떻게 만드는지의 세부 내용을 제공할 수는 없지만, 여기에는 기본 원칙들이 있다.”
이 논문과 LeCun의 인터뷰에서는 LeCun이 깊은 학습에 대한 대안으로 에너지 기반의 자기 지도 학습을 주장하는 방향으로 나아가기를 희망하는 그의 핵심 접근 방식을 이해하는 데 도움이 되는 ENBLE과의 인터뷰를 읽으면 더욱 잘 이해할 수 있다.
로봇 공학
- AI 기반 보조적인 인공지능 손으로 디자인과 스타일을 삶을 바꾸는 제품
- 현재 이용 가능한 최고의 로봇 청소기
- 왜 대학생들만 멋진 로봇을 가질까요?
- 최고의 로봇 잔디깎이: 노동력 없는 잔디 관리
아래는 인터뷰의 가볍게 편집된 대본입니다.
ENBLE: 우리의 대화 주제는 “자율 기계 지능으로 가는 길”입니다. 현재 버전 0.9.2가 유지되고 있습니다, 맞나요?
Yann LeCun: 네, 저는 이것을 종류로 일종의 작업 문서로 간주합니다. 그래서 Open Review에 게시하고 사람들의 의견과 제안, 추가적인 참고 자료를 기다리고, 그 후에 수정된 버전을 제작할 것입니다.
ENBLE: Juergen Schmidhuber가 이미 Open Review에 일부 의견을 추가했다고 보입니다.
YL: 네, 그는 항상 그렇게 합니다. 저는 내 논문에서 그의 논문 중 하나를 인용했습니다. 그가 소셜 네트워크에서 제기한 주장은 1991년에 이 모든 것을 그가 발명했다는 것인데, 그는 다른 경우에도 그렇게 했습니다. 하지만 그게 사실이 아니라고 생각합니다. 그는 그냥 아이디어를 가지고 있다는 것과 그 아이디어를 가지고 장난감 문제에서 작동시키고 실제 문제에서 작동시키고 작동 원리를 보여주는 이론을 만들고 그것을 배치하는 것 사이에 큰 차이가 있습니다. 그의 과학적 인정에 대한 생각은 그것이 그것을 처음 생각한 사람이 모든 인정을 받아야 한다는 것입니다. 그것은 말도 안 되는 겁니다.
(업데이트: Jürgen Schmidhuber는 “LeCun은 내가 ‘과학적 인정에 대한 나의 생각은 그것을 처음 생각한 사람이 모든 인정을 받아야 한다는 것’이라 주장한다. 어느 우주에서도 이것은 사실이 아니다. 나는 [DLC]에 썼듯이 ‘중요한 방법의 발명자는 해당 방법을 발명한 사람에게 인정을 받아야 한다. 항상 그 방법을 대중화시키는 사람이 아닐 수도 있다. 그런 다음 대중화시키는 사람은 대중화시키기 위해 인정을 받아야 한다(하지만 발명한 사람으로는 인정받지 않는다).’ 그러나 LeCun은 다른 사람들의 발명을 대중화하는 데 대한 인정에 만족하지 않는 것 같다. 그는 발명자의 인정도 원한다. 그는 기본적으로 과학적 진실성의 기본적으로 받아들여진 규칙과 모순되는, 지지할 수 없는 입장을 고수하고 있다.”라고 답변했다.)
ENBLE: 소셜 미디어에서 듣는 모든 말을 믿지 마세요.
YL: 말하자면, 그 사람이 나에게 인용하라고 한 주요 논문은 내 논문에 언급하는 주요 아이디어가 전혀 없습니다. 그는 이를 GAN 및 다른 것들과도 함께 했는데, 이는 사실이 아니었습니다. 특정 논문에서는 이것이 보통 의미에서의 과학 논문이 아니라는 것을 명시적으로 언급했습니다. 이것은 이 주제가 어디로 가야하는지에 대한 입장 논문입니다. 여기에는 새로운 아이디어가 몇 가지 있을 수 있지만 대부분은 그렇지 않습니다. 그 논문에 쓴 대부분의 것에 대한 우선권을 주장하지 않습니다.
(업데이트: 슈미드후버는 “LeCun이 나에 대해 주장한 것: ‘… 그가 인용하라고 말한 주요 논문에는 내가 논문에서 언급한 주요 아이디어가 전혀 없다.’ 이것은 전혀 말이 되지 않는다. 나는 LeCun이 그가 자신의 ‘주요 원저적 기여’라고 명시적으로 부른 대부분을 포함한 여러 관련 논문(AC90, UN1, AC02, HRL1, PLAN4)을 나열했다. LeCun은 [LEC22c]라고 말했습니다: ‘나는 내가 그 논문에 쓴 대부분에 대한 우선권을 주장하지 않고 있다.’ 그러나 그는 그의 ‘주요 원저적 기여’ [LEC22a]를 나열했고, 나는 그것이 아무것도 아니라는 것을 보여주었다. LeCun은 나에 대해 ‘그는 GAN도 이렇게 했었다.’라고 주장했다. 이 거짓 주장은 정당화할 수도 없고, 참조할 수도 없다. 나의 기울기 기반 생성 및 적대적 NN은 1990년에 (자주 인용되고 구현되고 사용되는) 기본 원리를 설명하는 GAN의 2014 논문 [GAN1]은 올바르게 크레딧을 할당하지 못했다 [T22]. 이에 대한 나의 피어 리뷰 논문 [AC20]은 도전받지 않았다.)
강화학습은 또한 충분하지 않다고 LeCun은 주장합니다. DeepMind의 David Silver와 같은 연구자들은 체스, 쇼기 및 바둑을 마스터한 AlphaZero 프로그램을 개발했지만, LeCun은 “그들은 매우 행동 중심적이다”라고 관찰했습니다. 그러나 “우리가 하는 대부분의 학습은 실제로 행동을 취하는 것이 아니라 관찰을 통해 합니다.”
ENBLE: 그리고 그것은 시작하기에 좋은 곳인 것 같습니다. 왜 이 경로를 선택했는지 궁금합니다. 어떤 생각으로 이를 고민하게 되었나요? 왜 이것을 쓰고 싶었나요?
YL: 그래서 매우 오랜 시간 동안 인간 수준이나 동물 수준의 지능이나 학습 및 능력을 향한 경로에 대해 생각해 왔습니다. 제 강의에서 나는 이러한 종류의 학습을 동물과 인간에서 관찰하는 것을 모방하는 데는 지도 학습과 강화 학습이 충분하지 않다고 명확하게 주장해 왔습니다. 이를 7~8년 정도 한 것 같습니다. 그래서 이것은 최근의 일이 아닙니다. 몇 년 전에 NeurIPS에서 주요 강연을 하여 이 점을 남겼고, 여러 강의도 있으며 녹음된 내용도 있습니다. 그렇다면 왜 이제서야 논문을 쓰려고 했나요? 우리는 시간이 떨어지고 있다고 보기 때문입니다. 우리는 젊지 않습니다.
ENBLE: 60은 새로운 50이다.
YL: 맞아요, 그렇지만 핵심은 우리가 인공 지능의 인간 수준으로 나아가기 위해 어떻게 해야 하는지에 대한 많은 주장들이 있다는 것입니다. 그리고 나는 그 중에서도 잘못된 방향으로 가는 아이디어들이 있다고 생각합니다. 그 중 하나는 우리가 신경망 위에 상징적 추론을 추가하기만 하면 된다는 것입니다. 그러나 이것을 어떻게 해야 할지 모릅니다. 따라서 아마도 내가 논문에서 설명한 것이 명시적인 기호 조작 없이 동일한 작업을 수행하는 한 가지 접근 방식이 될 수 있습니다. 이것은 전통적인 Gary Marcus와 같은 사람들의 접근 방식입니다. 그런데, Gary Marcus는 AI 전문가가 아니라 심리학자입니다. 그는 AI에 대해 아무 기여도 하지 않았습니다. 그는 실험적 심리학에서 정말 좋은 일을 했지만 AI에 대한 피어 리뷰 논문은 절대로 쓴 적이 없습니다. 그런 사람들이 있습니다.
(업데이트: Gary Marcus는 피어 리뷰된 논문의 부족에 대한 주장을 반박합니다. 그는 ENBLE로 전자 메일에서 다음과 같은 피어 리뷰된 논문들을 제공했습니다: 인공 지능에서 극도로 불완전한 정보를 활용한 컨테이너에 대한 상식적 추론; 인공 지능에서 극도로 불완전한 정보로부터의 추론: 컨테이너의 경우에 대한 인지 시스템의 진보; 자동 추론에서 시뮬레이션의 범위와 한계; ACM 통신에서의 상식적 추론과 상식적 지식; 연결주의적 연결주의를 재고하다, 인지 심리학)
세상에는 [DeepMind 주요 연구 과학자] David Silvers와 같은 사람들이 있습니다. 보상이 충분하다고 말하는데, 기본적으로 강화학습에 관한 모든 것이며, 조금 더 효율적으로 만들기만 하면 된다고 말합니다. 그들은 틀리지 않았다고 생각하지만, 강화학습을 더 효율적으로 만들기 위해 필요한 단계는 결국 강화학습을 케이크 위의 체리로 만들 것입니다. 그리고 그 핵심적으로 부족한 부분은 행동 없이 관찰을 통해 세계가 어떻게 작동하는지 배우는 것입니다. 강화학습은 행동 중심적인 방식으로 작동하며, 행동을 취하고 결과를 보는 것으로 세계에 대해 배웁니다.
ENBLE: 그리고 보상에 초점을 맞춥니다.
YL: 그렇습니다. 보상에 초점을 맞추고 행동에도 초점을 맞춥니다. 따라서 세계에 대해 배우려면 세계에서 행동을 취해야 합니다. 그리고 제 논문에서 주장하는 주요한 점은, 우리가 하는 대부분의 학습은 실제로 행동을 취하는 것이 아니라 관찰을 통해 이루어진다는 것입니다. 이는 강화학습 연구자들에게는 매우 비전통적인 접근이지만, 심리학자와 인지과학자들 중에도 행동이 중요하다고 생각하는 사람들에게도 그렇습니다. 행동은 필수적이라고 말하고 싶지는 않지만, 우리가 배우는 대부분은 주로 세계의 구조에 관한 것이며, 물론 상호작용과 행동, 놀이 등이 포함되지만, 그 중 상당 부분은 관찰적인 것입니다.
ENBLE: 동시에 Transformer 사용자와 언어 중심의 사람들을 화나게 해볼 것 같네요. 언어 없이 이걸 어떻게 만들 수 있을까요? 아마도 많은 사람들을 화나게 할 것 같습니다.
YL: 네, 저는 그런 것에 익숙합니다. 그래서 언어 중심의 사람들은 지능은 언어에 관한 것이며, 지능의 기반은 언어라고 말합니다. 하지만 이는 동물의 지능을 배제하는 것입니다. 우리의 지능적인 기계들이 고양이만큼의 상식을 갖는 것은 아직 아닙니다. 그러니 우리는 왜 이곳에서 시작하지 않을까요? 고양이가 주변 세계를 이해하고, 동물들이 더 나은 계획을 세우고, 똑똑한 행동을 할 수 있는 것은 무엇일까요?
그리고 우리가 서로 대화하고 정보를 교환하면서 지능적이라고 말하는 사회적인 측면이 있는 사람들도 있습니다. 그러나 부모와 결코 만나지 않는 같은 종류의 사회적이지 않은 동물들도 매우 똑똑합니다. 예를 들어 문어나 오랑우탄입니다. 물론 오랑우탄은 어머니에게 교육을 받지만, 사회적 동물은 아닙니다.
하지만 또 다른 분류의 사람들은 스케일링만으로 충분하다고 말하는 사람들입니다. 그래서 우리는 거대한 Transformer를 사용하고, 비디오, 텍스트 등을 포함한 다중 모달 데이터로 그들을 훈련시키고, 모든 것을 토큰화하고, 이산적인 예측을 할 수 있도록 거대한 모델을 훈련시키는 것입니다. 그들은 맞지 않습니다. 그것은 미래의 지능 시스템의 구성 요소가 될 수도 있지만, 필수적인 부분이 빠져 있다고 생각합니다.
Space
- Artemis는 무엇인가요? NASA의 새로운 달 탐사에 대해 알아보세요.
- NASA는 Voyager 1의 이상한 데이터 전송의 수수께끼를 풀었습니다.
- NASA의 새로운 작고 강력한 레이저가 달에서 물을 찾을 수 있을 것입니다.
- NASA는 영감을 주는 길을 개척하고 있습니다. 우리는 모두가 그 길을 따라갈 수 있도록 해야 합니다.
이 논문으로 다른 분류의 사람들도 화나게 할 것입니다. 그것은 확률론자들, 종교적인 확률론자들입니다. 확률 이론만 사용하여 기계 학습을 설명할 수 있다고 생각하는 사람들입니다. 그리고 저는 이 글에서 설명하려고 한대로, 세계 모델이 완전히 확률적이어야 한다는 것은 너무 많은 것을 요구하는 것입니다. 우리는 그것을 어떻게 해야 할지 모릅니다. 연산의 불가능성이 있습니다. 그래서 저는 이 아이디어를 완전히 버리기를 제안합니다. 물론, 이것은 기계 학습뿐만 아니라 통계학의 거대한 기둥이기도 합니다. 통계학은 기계 학습을 위한 정상적인 형식이라고 주장합니다.
그리고 다른 것은 —
ENBLE: 잘 하고 있어요…
YL: —라는 것은 생성 모델이라 불리는 것입니다. 그래서, 예측을 배울 수 있고, 예측을 통해 세상에 대해 많은 것을 배울 수 있다는 아이디어입니다. 그래서, 비디오 한 조각을 주고 시스템에게 비디오에서 다음에 어떤 일이 일어날지 예측하도록 요청할 수 있습니다. 그리고 세부 사항을 포함한 실제 비디오 프레임을 예측하도록 요청할 수도 있습니다. 그러나 논문에서 주장한 것은 이렇게 하는 것은 실제로 요구하는 것이 너무 많고 복잡하다는 것입니다. 그리고 이것은 내가 생각을 바꾼 것입니다. 2년 정도 전까지, 내가 라텐트 변수 생성 모델이라고 부르는 모델들을 옹호했습니다. 미래에 무엇이 일어날지 또는 누락된 정보를 예측하는 모델들이었는데, 이 예측이 결정론적이지 않을 경우에는 잠재 변수의 도움을 받을 수도 있습니다. 그러나 이것을 포기했습니다. 그리고 이것을 포기한 이유는 경험적인 결과에 기반합니다. 사람들이 BERT와 같은 대형 언어 모델에서 사용되는 예측 또는 재구성 기반 훈련을 이미지에 적용해 보았는데, 그것은 완전한 실패였습니다. 그리고 이것이 완전한 실패인 이유는, 다시 말하면, 확률적 모델의 제약 때문입니다. 단어와 같은 이산 토큰을 예측하는 것은 상대적으로 쉽기 때문에 사전의 모든 단어에 대한 확률 분포를 계산할 수 있습니다. 그건 쉬워요. 그러나 시스템에게 모든 가능한 비디오 프레임에 대한 확률 분포를 생성하도록 요청하면, 그것을 어떻게 매개변수화할지 모르거나, 어떻게 정규화할지 모릅니다. 우리는 해결할 수 없는 수학적 문제에 부딪힙니다.
“우리의 지능적인 기계가 고양이만큼의 상식을 가지지 못한 시점에 우리는 아직 도달하지 못했습니다,” 라쿤은 말합니다. “그래서, 우리는 여기서 시작해볼까요? 고양이가 주변 세계를 이해하고, 꽤 똑똑한 일들을 할 수 있으며, 계획을 세우고 그런 일들을 하는 데 필요한 것은 무엇인가요? 그리고 개들은 더 잘할 수 있죠?”
그래서, 그래서 나는 확률 이론 또는 그러한 것들을 위한 프레임워크, 보다 약한 것인 에너지 기반 모델을 포기하자고 말하는 것입니다. 나는 이것을 수십 년 동안 옹호해 왔으므로, 최근 일이 아닙니다. 그러나 동시에, 생성 모델의 아이디어를 포기하는 이유는 세상에는 이해할 수 없고 예측할 수 없는 많은 것들이 있기 때문입니다. 엔지니어라면 그것을 노이즈라고 부를 수 있습니다. 물리학자라면 열이라고 부를 수 있습니다. 그리고 기계 학습 전문가라면, 관련 없는 세부 사항이나 뭐 그런 걸로 부를 수 있습니다.
그래서, 논문에서 사용한 예시나 발표에서 사용한 예시는, 자율주행차에 도움이 되는 세계 예측 시스템이 필요하다고 합니다. 다른 차들의 궤적이 미리 예측되어야 하고, 움직일 수도 있는 다른 물체들, 보행자, 자전거, 축구공을 뒤따라 달리는 아이와 같은 것들이 어떻게 될지 예측해야 합니다. 세상에 대한 여러 가지 것들. 그러나 도로 가장자리에는 나무가 있을 수 있고, 오늘은 바람이 불어서 잎들이 움직이고 있을 것입니다. 그리고 나무 뒤에는 연못이 있고, 연못에는 파문이 있을 것입니다. 그리고 이러한 것들은 본질적으로 예측할 수 없는 현상입니다. 그리고 모델이 그런 예측하기 어렵고 관련 없는 것들에 상당한 자원을 소비하는 것을 원치 않습니다. 그래서 나는 결합된 임베딩 아키텍처를 옹호하고 있습니다. 모델하려는 변수는 예측하려는 것이 아니라 모델링하려는 것이며, 그 모델은 인코더를 통해 흐른다. 그 인코더는 입력에 대한 관련 없거나 복잡한 세부 사항을 제거할 수 있습니다. 기본적으로 노이즈에 해당합니다.
ENBLE: 이번 해에 우리는 에너지 기반 모델, JEPA와 H-JEPA에 대해 이야기했습니다. 내 감각에 따르면, 올바르게 이해했다면, X와 Y 임베딩의 두 가지 예측이 가장 유사한 저에너지 지점을 찾는 것 같아요. 이는 한 곳에 비둘기가 있고, 장면의 배경에 무언가 있는 경우, 이들은 서로 가까운 임베딩을 만드는 중요한 지점이 아닐 수 있습니다.
YL: 맞습니다. JEPA 아키텍처는 실질적으로 입력에 대해 최대한 정보를 추출하는 것과 상호 예측 가능성 또는 신뢰성 수준을 가진 서로에게 유사한 임베딩을 만드는 것 사이의 절충안을 찾으려고 합니다. 그것은 절충안을 찾습니다. 그래서, 잎의 움직임과 같은 세부 사항을 포함한 자원의 거대한 양을 소비하는 선택과 잎이 1초 후에 어떻게 움직일지를 결정할 동적을 모델링하는 것 사이에서 선택해야 할 경우, 단순히 Y 변수를 통해 모든 이러한 세부 사항을 제거하는 예측기를 실행함으로써 그것을 제거할 것입니다. 왜냐하면 모델링하고 포착하기 너무 어렵기 때문입니다.
인공지능
- 7가지 고급 ChatGPT 프롬프트 작성 팁
- 2023년 최고의 ChatGPT 플러그인 10가지 (그리고 그것들을 최대한 활용하는 방법)
- 일하면서 많은 AI 도구를 시험해봤습니다. 지금까지 내가 가장 좋아하는 5가지입니다.
- 인간인가 봇인가? 이 튜링 테스트 게임으로 당신의 AI 식별 기술을 시험해보세요.
ENBLE: 놀랍게도, 당신은 “작동한다면, 나중에 이를 설명할 열역학 이론을 찾아낼 것이다”라고 주장하는 큰 옹호자였습니다. 여기서는 “우리가 어떻게 이를 해결할지 모르겠지만, 이에 대해 생각할 몇 가지 아이디어를 제시하고자 합니다”라는 접근 방식을 취하고 있으며, 아마도 이론이나 가설에 접근하고 있습니다. 그것은 흥미로운 점입니다. 왜냐하면 자율주행 자동차가 공통 감각을 갖고 있느냐 없느냐와 상관없이 보행자를 인식할 수 있는 자동차에 많은 돈을 투자하고 있는 많은 사람들이 있다고 상상하기 때문입니다. 그리고 그 사람들 중 일부는 “그건 괜찮아, 우리는 공통 감각이 없어도 괜찮아, 우리는 시뮬레이션을 구축했고, 시뮬레이션이 놀라운 성능을 보여주고 있으며, 계속해서 개선하고, 시뮬레이션을 확장할 것이다”라고 말할 것입니다.
따라서, 지금은 우리가 하는 일에 대해 한 발 물러서서 생각해보자는 것은 흥미롭습니다. 산업은 계속해서 확장하고 확장하고 확장하고 확장할 것이라고 말하고 있습니다. 즉, 그 꼭두각시가 정말로 작동합니다. 즉, GPU의 반도체 꼭두각시는 정말로 작동합니다.
YL: 여기에는 다섯 가지 질문이 있습니다. 그래서, 나는 확장이 필요하다는 것을 비판하고 있는 것은 아닙니다. 우리는 확장해야 합니다. 그 신경망은 커질수록 더 좋아집니다. 확장해야 한다는 것에 의문의 여지는 없습니다. 이해가 있는 것은 일부분의 공통 감각을 갖고 있는 것입니다. 그것은 큰 것일 것입니다. 나는 그런 일이 피할 수 없다고 생각합니다. 그래서 확장은 좋고 필요하지만 충분하지는 않습니다. 그게 내가 말하려는 바입니다. 그건 첫 번째로 말하고 있는 것입니다.
두 번째로, 이론이 먼저 오고 그런 것들입니다. 그래서, 나는 먼저 나오는 개념이 있다고 생각합니다. “우리는 이 사다리를 만들었지만, 우리는 달에 가고 싶고 이 사다리는 우리를 달에 이르게 할 수 없습니다. 그래서, 여기서 내가 쓰는 것은 로켓을 만들어야 한다는 것입니다. 로켓을 어떻게 만드는지에 대한 세부 사항은 제공할 수 없지만, 여기 기본 원칙이 있습니다. 이에 대한 이론이나 무언가를 작성하고 있는 것은 아니지만, 이건 로켓이 될 것입니다. 좀 더 정확히는 우주 엘리베이터일 수도 있습니다. 우리는 모든 기술의 세부 사항을 갖고 있지 않을 수도 있습니다. 우리는 JEPA에 대해 작업하고 있습니다. Joint embedding은 이미지 인식에 대해 아주 잘 작동합니다. 하지만 이를 사용하여 세계 모델을 훈련시키려면 어려움이 있습니다. 우리는 이에 대해 작업하고 있으며, 곧 작동하게 만들 수 있기를 희망합니다. 하지만 아마도 극복할 수 없는 어려움에 직면할 수도 있습니다.
그런 다음 논문에서는 계획을 할 수 있도록 시스템이 가지고 있어야 하는 중요한 아이디어가 있습니다. 계획은 단순한 형태의 추론으로 생각할 수 있습니다. 계획하려면 잠재 변수가 필요합니다. 즉, 어떤 신경망에 의해 계산되지 않는 것들이며, 어떤 목적 함수나 비용 함수를 최소화하기 위해 추론되는 값입니다. 그리고 이 비용 함수를 사용하여 시스템의 동작을 조종할 수 있습니다. 이것은 전혀 새로운 아이디어가 아닙니다, 맞습니까? 이것은 매우 고전적인 최적 제어로, 이의 기초는 50년대 후반, 60년대 초반까지 거슬러 올라갑니다. 그래서, 여기에 새로운 것이라고 주장하고 있는 것은 아닙니다. 하지만 내가 말하고 있는 것은 계획을 할 수 있는 지능적인 시스템의 일부로 이러한 유형의 추론이 포함되어야 하며, 그 동작을 하드코딩된 행동이 아닌 목적 함수에 의해 지정하거나 조절할 수 있어야 한다는 것입니다. 학습을 주도하는 것이 아니라 동작을 주도하는 이 목적 함수는 학습을 주도하지 않을 수도 있지만 동작을 주도합니다. 우리 뇌에는 그런 것이 있고, 모든 동물은 사물에 대한 내재적인 비용이나 내재적인 동기를 갖고 있습니다. 아홉 개월 된 아기는 일어서기를 원합니다. 일어서면 행복해지는 비용, 그 비용 함수의 항은 하드코딩되어 있습니다. 그러나 어떻게 일어서는지는 학습입니다.
“확장은 좋고 필요하지만 충분하지 않습니다,”라고 LeCun은 GPT-3과 같은 거대한 언어 모델인 Transformer 기반 프로그램에 대해 말합니다. Transformer의 추종자들은 “우리는 모든 것을 토큰화하고, 거대한 모델을 훈련시켜 이산적인 예측을 만들고, 어떻게든 AI가 이를 통해 등장할 것이다… 하지만 나는 이 핵심 부분을 놓치고 있다고 생각합니다.”
ENBLE: 이 포인트를 마무리 짓기 위해, 딥 러닝 커뮤니티의 많은 사람들은 상식이 없는 것을 고집하는 것처럼 보입니다. 여기서 어느 정도 대립점이 생기는 것 같습니다. 어떤 사람들은, 우리는 상식을 갖춘 자율주행차가 필요하지 않다고 말합니다. 확장을 통해 해결할 수 있을 것입니다. 하지만 당신이 말하고 있는 것은 그런 경로를 계속 가는 것은 괜찮지 않다는 것이라는 것 같습니다.
YL: 알겠습니다. 상식이 없는 레벨 5 자율주행차가 출시될 가능성이 완전히 있습니다. 그러나 이 접근 방식의 문제는 이것이 일시적인 것이 될 것이라는 것입니다. 왜냐하면 여러분은 엄청난 노력을 기울여야 할 것입니다. 예를 들어 전체 세계를 지도화하고, 특정한 꼭짓점 상황에 대한 동작을 하드웨어로 구축하고, 도로에서 마주할 수 있는 이상한 상황들을 충분한 데이터를 수집하여 이를 해결해야 합니다. 그리고 제 추측은 충분한 투자와 시간이 있다면, 여러분은 엄청난 노력을 기울여 문제를 해결할 수 있을 것이라는 것입니다. 그러나 궁극적으로는 더욱 만족스럽고 더 나은 해결책이 있을 것으로 생각됩니다. 이는 세계가 작동하는 방식을 더 잘 이해하는 시스템과 관련이 있으며, 인간 수준의 상식이 필요하지는 않지만, 시스템이 관찰을 통해 습득할 수 있는 어떤 종류의 지식이 필요합니다. 누군가가 운전하는 것을 보는 것이 아니라 주변에서 움직이는 것을 관찰하고 세상에 대해 많은 이해를 갖추며, 세상이 어떻게 작동하는지에 대한 배경 지식을 구축한 뒤에 운전을 배울 수 있게 될 것입니다.
이에 대한 역사적인 예를 들어보겠습니다. 고전적인 컴퓨터 비전은 여러 하드웨어 모듈 위에 기반하여 구축되었고, 그 위에는 일종의 학습을 위한 얇은 레이어가 있었습니다. 2012년에 AlexNet에 의해 이러한 방식은 극복되었으며, 첫 번째 단계로는 SIFT(Scale-Invariant Feature Transform)와 HOG(Histogram of Oriented Gradients)와 같은 수작업으로 만들어진 특징 추출 및 중간 수준의 특징, 그리고 비지도 학습 방법을 기반으로 한 두 번째 레이어, 그리고 서포트 벡터 머신 또는 비교적 간단한 분류기를 두는 것이 표준 파이프라인이었습니다. 이 접근 방식은 2000년대 중반부터 2012년까지 사용되었습니다. 그리고 이것은 end-to-end 합성곱 신경망에 의해 대체되었는데, 여기서는 이러한 수작업이 필요하지 않고 많은 양의 데이터를 사용하여 끝에서 끝까지 모델을 훈련시키는 것입니다. 이것은 제가 오랫동안 주장해왔던 접근 방식이었지만, 그 동안에는 대형 문제에는 적용하기 어려웠습니다.
음성 인식에서도 비슷한 이야기가 있었습니다. 다시 말해서, 데이터 전처리를 위한 상세한 엔지니어링, 대량의 켑스트럼(신호 처리를 위한 Fast Fourier Transform의 역) 추출, 그리고 사전에 설정된 아키텍처와 함께 은닉 마르코프 모델, 혼합 가우시안 등이 사용되는 방식이었습니다. 그래서 이는 비전에서와 비슷한 구조이고, 수작업으로 만든 프론트엔드와 어느 정도의 비지도 학습을 거친 중간 레이어, 그리고 그 위에 지도 학습을 하는 레이어로 구성되어 있습니다. 그리고 이것은 지금은 엔드 투 엔드 신경망에 의해 거의 완전히 대체되었습니다. 따라서 저는 어떤 의미에서는 모든 것을 학습하려고 하는 시도를 보고 있지만, 그것에는 올바른 사전 지식, 올바른 아키텍처, 올바른 구조가 필요하다고 생각하고 있습니다.
Waymo와 Wayve와 같은 스타트업과 같은 자율주행차 시장은 “데이터를 투입하고 거의 모든 것을 배울 수 있다”고 생각해 “조금 너무 낙관적이었다고” 그는 말합니다. ADAS의 레벨 5 자율주행차는 가능하지만, “그러나 엄청난 노력이 필요하고” 결과물은 초기 컴퓨터 비전 모델과 같이 “취약”할 것입니다.
ENBLE: 당신이 말하는 것은, 어떤 사람들은 현재 딥 러닝이 산업에 적용되지 않는 것을 엔지니어링하려고 하고, 그것이 컴퓨터 비전에서 오래된 기술이 되는 것을 만들어 낼 것이라는 것인가요?
YL: 맞습니다. 그리고 이것이 지난 몇 년 동안 자율주행에 종사하는 사람들이 조금 너무 낙관적이었던 이유 중 하나입니다. 합성곱 신경망과 트랜스포머와 같은 일반적인 모델들이 있으며, 데이터를 투입하면 거의 모든 것을 학습할 수 있다고 생각합니다. 그래서, 그 문제의 해결책을 가지고 있다고 말합니다. 첫 번째로 할 일은 자율주행차가 아무도를 다치지 않고 몇 분 동안 스스로 운전하는 데 성공하는 데모를 만드는 것입니다. 그런 다음 모서리 케이스가 많다는 것을 깨닫고, 훈련 세트를 두 배로 늘릴 때 얼마나 더 나아지는지 곡선을 그리려고 하는데, 모든 종류의 모서리 케이스가 있기 때문에 그곳에 도달할 수 없다는 것을 깨닫게 됩니다. 그리고 여러분은 2억 킬로미터를 주행할 때마다 치명적인 사고를 일으키지 않는 자율주행차를 가져야 한다는 것을 깨닫게 됩니다. 그래서, 여러분은 두 가지 방향으로 나뉩니다.
첫 번째 방향은 시스템이 학습하는 데 필요한 데이터 양을 어떻게 줄일 수 있는지입니다. 그리고 그것이 자기 지도 학습(self-supervised learning)의 역할입니다. 그래서 많은 자율주행 자동차 기업들은 자기 지도 학습에 매우 관심이 있습니다. 왜냐하면 자기 지도 학습은 모방 학습을 위한 엄청난 양의 감독 데이터를 여전히 사용하면서 사전 훈련을 통해 성능을 더욱 향상시킬 수 있는 방법입니다. 아직 완전히 성공한 것은 아니지만, 곧 성공할 것입니다. 그리고 다른 옵션도 있습니다. 현재 더 발전된 대부분의 회사들이 채택한 방법은 엔드 투 엔드(end-to-end) 훈련을 할 수 있지만, 처리할 수 없는 많은 예외 상황들이 있기 때문에 이들 예외 상황을 처리할 수 있는 시스템을 따로 설계하고, 기본 동작을 처리하기 위해 제어를 하드웨어로 구현하는 것입니다. 충분한 수의 엔지니어 팀이 있다면 이를 해낼 수 있을지도 모릅니다. 하지만 시간이 많이 걸리고 결국은 약간 취약할 것입니다. 반면에 앞으로 나타날 수 있는 학습 기반 접근 방식은 어느 정도의 상식과 세상이 어떻게 작동하는지에 대한 이해를 갖고 있기 때문에 이런 취약성을 갖지 않을 것입니다.
단기적으로는, 어떤 식으로든 설계된 접근 방식이 승리할 것입니다. 이미 Waymo와 Cruise와 같은 기업들이 그렇게 하고 있습니다. 그런 다음 자기 지도 학습 접근 방식이 설계된 접근 방식의 발전을 도울 것입니다. 그러나 장기적으로는 이러한 기업들이 기대 수준에 도달하기 전에 사람들이 인내심을 잃거나 돈을 다 쓸 가능성이 있습니다.
ENBLE: 모델에서 선택한 몇 가지 요소들을 선택한 이유에 대해 어떤 흥미로운 이야기가 있는지 말씀해 주실 수 있을까요? Kenneth Craik [1943,The Nature of Explanation]와 Bryson과 Ho [1969, Applied optimal control]을 인용하셨는데, 특히 이들이 이룬 것을 잘 해냈다고 믿으셨기 때문에 이들에게서 시작한 이유에 대해 궁금합니다. 왜 이들로부터 시작하셨나요?
YL: 음, 제가 생각하기에 그들이 모든 세부 사항을 완벽히 이해한 것은 아닙니다. Bryson과 Ho, 이 책은 1987년에 토론토의 Geoffrey Hinton과 함께 포스닥으로 있을 때 읽은 책입니다. 그러나 나는 내가 박사 학위를 쓰는 동안 이 분야의 연구에 대해 알고 있었고, 최적 제어와 역전파 사이의 연결을 만들어 냈습니다. 실제로 역전파의 진짜 발명자는 실제로 최적 제어 이론가인 Henry J. Kelley, Arthur Bryson, 심지어는 레프 폰트리아긴(Lagrange mechanics, 1950년대 말의 러시아 최적 제어 이론가)이었다고 할 수 있습니다.
그들은 이것을 발견했고, 실제로 그 아래에 있는 수학은 라그랑지안 역학(Lagrangian mechanics)입니다. 실제로 오일러와 라그랑지에게로 돌아갈 수 있으며, 그들의 고전적 역학의 정의에서 이에 대한 힌트를 찾아볼 수 있습니다. 따라서 최적 제어의 맥락에서 이들은 기본적으로 로켓 궤적을 계산하는 것에 관심이 있었습니다. 이것은 초기 우주 시대였습니다. 그리고 만약 로켓의 모델이 있다면, 시간 t에서 로켓의 상태와, 내가 할 행동, 즉 추진력과 다양한 액추에이터들이 주어지면, 시간 t+1에서 로켓의 상태가 됩니다.
ENBLE: 상태-액션 모델, 가치 모델.
YL: 맞습니다, 제어의 기초입니다. 그래서 이제 명령어의 순서를 상상하여 로켓을 쏘는 것을 시뮬레이션할 수 있으며, 로켓과 목표물(우주 정거장 등) 사이의 거리를 비용 함수로 가질 수 있습니다. 그리고 어떤 종류의 경사 하강법을 사용하여 어떻게 하면 로켓이 가능한 한 목표물에 가까워질 수 있는지 알아낼 수 있습니다. 이는 시간을 거슬러 역방향으로 신호를 역전파함으로써 이루어집니다. 그리고 이것이 역전파, 경사 역전파입니다. 이 신호들은 라그랑지안 역학에서 공액 변수(conjugate variables)라고 불리지만, 실제로 그것들은 기울기입니다. 그래서 그들은 역전파를 발명했지만, 이 원리를 패턴 인식이나 그와 유사한 작업을 수행할 수 있는 다단계 시스템을 훈련시키는 데 사용할 수 있다는 것을 깨닫지 못했습니다. 이것은 실제로 1970년대 후반, 1980년대 초에 알려지기 시작했으며, 실제로 구현되고 동작하기 시작한 것은 1980년대 중반이었습니다. 그래서 이것이 역전파가 실제로 대폭 발전한 곳입니다. 여기에는 몇 줄의 코드로 다단계 신경망을 훈련시킬 수 있다는 것을 보여주는 사람들이 있었습니다. 이것은 퍼셉트론의 한계를 해소시킵니다. 그리고, 최적 제어와의 연결이 있긴 하지만, 그래도 상관없습니다.
ENBLE: 그래서, 이 처음 시작한 영향력들은 역전파로 돌아가는 것이었고, 그게 당신에게는 출발점으로서 중요한 역할을 했던 건가요?
YL: 응, 하지만 사람들이 조금 잊은 것은, 90년대나 80년대에도 이에 대한 꽤 많은 연구가 있었다는 거죠. 마이클 조던 [MIT 뇌과학 및 인지과학 학과] 같은 사람들도 포함해서, 그들은 이제 신경망을 다루지는 않지만 신경망을 제어에 사용할 수 있고, 최적 제어에 대한 고전적인 아이디어를 사용할 수 있다는 생각이었죠. 그래서 모델-예측 제어라고 불리는 것들처럼, 시스템을 제어하려는 목적이 있는 경우, 시스템과 그 환경에 대한 좋은 모델이 있다면 일련의 동작의 결과를 시뮬레이션하거나 상상할 수 있다는 아이디어입니다. 그리고 그 후에 기울기 하강법을 통해, 이것은 학습이 아니라 추론이죠, 목적을 최소화하는 최적의 동작 순서를 찾아낼 수 있습니다. 그래서 추론을 위해 잠재 변수를 가진 비용 함수의 사용은 현재 대규모 신경망들이 잊고 있는 것 같습니다. 하지만 이는 오랜 기간 동안 기계 학습의 매우 고전적인 구성 요소였습니다. 그래서 베이지안 네트, 그래프 모델 또는 확률적 그래픽 모델은 이러한 추론 유형을 사용했습니다. 여러 변수 간의 의존성을 포착하는 모델이 있는데, 일부 변수의 값을 알려줬을 때, 나머지 변수의 가장 가능성이 높은 값을 추론해야 합니다. 그것이 그래프 모델과 베이지안 네트의 추론의 기본 원리입니다. 그리고 그것이 추론과 계획의 기본 원리가 되어야 한다고 생각합니다.
ENBLE: 당신은 비밀스런 베이지안이네요.
YL: 저는 비확률적인 베이지안입니다. 전에도 이런 장난을 친 적이 있습니다. 실제로 몇 년 전에 NeurIPS에 있었는데, 베이지안에게 “당신은 베이지안인가요?”라고 물어보는 동영상에 잡혔는데, “응, 저는 베이지안이에요. 하지만 저는 비확률적인 베이지안이에요, 그런 식으로 말하죠.
ENBLE: 확실히 스타 트렉에서 나온 것 같네요. 이 논문의 끝에서, 당신이 상상하는 것을 실현하기 위해서는 몇 년 동안 정말 어려운 작업이 필요하다고 언급했었죠. 현재 그 작업 중 일부에 대해 말해주실래요?
YL: 그래서, 논문에서 JEPA를 훈련하고 구축하는 방법을 설명했습니다. 그리고 저는 추출된 표현이 입력에 대해 가지는 정보 내용을 최대화하는 방법을 주장하고 있습니다. 그리고 두 번째로는 예측 오류를 최소화하는 것입니다. 그리고 예측기에 잠재 변수가 있어서 예측기가 비결정론적일 수 있게 하는 경우, 이 잠재 변수도 정보 내용을 최소화하여 정규화해야 합니다. 그래서 이제 두 가지 문제가 생기는데, 어떻게 하면 신경망의 출력의 정보 내용을 최대화하는가, 그리고 어떻게 하면 잠재 변수의 정보 내용을 최소화하는가입니다. 이 두 가지를 하지 않으면 시스템은 붕괴될 것입니다. 그것은 흥미로운 것을 아무 것도 배우지 못할 것이고, 모든 것에 영향력을 0으로 줄 것입니다. 이것은 의존성의 좋은 모델이 아닙니다. 이것이 제가 언급한 붕괴 방지 문제입니다.
그리고 사실상 사람들이 해온 모든 일 중에서 붕괴를 방지하기 위한 방법은 두 가지 범주뿐입니다. 하나는 대조적인 방법이고, 다른 하나는 정규화된 방법입니다. 그래서 이러한 두 개의 입력 표현의 정보 내용을 최대화하고 잠재 변수의 정보 내용을 최소화하는 아이디어는 정규화된 방법에 속합니다. 하지만 이러한 공동 임베딩 구조에 대한 많은 연구는 대조적인 방법을 사용하고 있습니다. 실제로 현재 가장 인기 있는 방법일 것입니다. 그래서 문제는 어떻게 하면 정보 내용을 측정하고 최적화하거나 최소화할 수 있는지에 대한 것입니다. 그리고 그곳에서 문제가 복잡해지는데, 우리는 실제로 정보 내용을 어떻게 측정하는지 모릅니다. 우리는 그것을 근사화할 수 있고, 상한선을 구할 수 있고, 그런 일을 할 수는 있습니다. 하지만 실제로 정보 내용을 측정하지는 않습니다. 사실, 어느 정도 정의되지도 않은 부분이기도 합니다.
ENBLE: 순간은 Shannon의 법칙이 아니죠? 정보 이론이 아니죠? 일정량의 엔트로피, 좋은 엔트로피와 나쁜 엔트로피, 좋은 엔트로피는 작동하는 기호 시스템이고, 나쁜 엔트로피는 노이즈입니다. 모든 것이 Shannon에 의해 해결되는 건 아니죠?
YL: 맞아요, 하지만 그 뒤에는 심각한 결함이 있습니다. 데이터가 당신에게 들어오고 그 데이터를 이산 기호로 양자화하고, 그런 다음 각 기호의 확률을 측정할 수 있다면, 그 기호가 운반하는 정보의 최대 양은 가능한 기호의 Pi log Pi의 합이 맞지요? 여기서 Pi는 기호 i의 확률이에요 – 셰넌 엔트로피라고 해요. [셰넌의 법칙은 일반적으로 H = – ∑ pi log pi로 표현됩니다.]
하지만 여기 문제가 있어요: Pi가 무엇인가요? 기호의 수가 적고 기호들이 독립적으로 추출된다면 쉽게 구할 수 있어요. 그러나 기호가 많고 종속성이 있는 경우 매우 어렵습니다. 그래서 비트 시퀀스가 있고 비트들이 서로 독립적이며 0 또는 1 사이와 같은 확률이 동일하다고 가정한다면 엔트로피를 쉽게 측정할 수 있어요. 하지만 당신에게 전달되는 것이 비디오 프레임과 같은 고차원 벡터라면, Pi가 무엇인가요? 분포는 어떻게 되나요? 먼저 이 고차원 연속 공간을 양자화해야 합니다. 이를 제대로 양자화하는 방법을 전혀 알지 못합니다. k-means 등을 사용할 수 있지만 이것은 근사치에 불과합니다. 그리고 독립성에 대한 가정을 해야 합니다. 그래서 비디오에서 연속된 프레임은 독립적이지 않다는 것은 명확합니다. 종속성이 있으며 해당 프레임은 한 시간 전에 본 동일한 사물의 사진이었던 다른 프레임에 의존할 수 있습니다. 그래서 Pi를 측정할 수 없습니다. Pi를 측정하려면 예측을 학습하는 기계 학습 시스템이 있어야 합니다. 그래서 다시 이전의 문제로 돌아옵니다. 따라서 정보의 측정은 근사치만 가능합니다.
“정확히 말하면 어떻게 하면 최적화하거나 최소화할 수 있는 방식으로 정보 내용을 측정합니까?”라고 LeCun은 말합니다. “그리고 그것이 복잡해지는 곳은 실제로 정보 내용을 어떻게 측정하는지 정확히 알지 못하기 때문입니다.” 지금까지 할 수 있는 최선은 원하는 작업에 “충분히 좋은” 대리자를 찾는 것입니다.
좀 더 구체적인 예를 들어볼게요. 우리가 실험하고 있고, 기사에서 언급한 알고리즘 중 하나는 VICReg라는 것인데, 이것은 분산 불변 공분산 규제라고 해요. 이것은 ICLR에서 출판된 별도의 논문에 있고, 약 2021년 전에 arXiv에 게재되었습니다. 여기서의 아이디어는 정보를 최대화하는 것입니다. 실제로 이 아이디어는 이전에 제 그룹이 발표한 Barlow Twins라는 논문에서 나왔어요. 신경망에서 나오는 벡터의 정보 내용을 최대화하기 위해, 기본적으로 변수들 사이의 유일한 종속성이 상관관계, 선형 종속성이라고 가정하는 거에요. 따라서, 변수들 간의 종속성이 가능한 유일한 종속성이라고 가정한다면, 시스템에서 나오는 정보의 내용을 최대화하기 위해 모든 변수가 0이 아닌 분산을 갖도록 해야 하며, 이를 다시 상관관계로 역상관시키는 백색화라고 불리는 동일한 과정을 거쳐야 합니다. 이것도 새로운 것은 아니에요. 하지만 이 방법의 문제는 변수 그룹들 또는 그냥 변수 쌍들 사이에 극히 복잡한 종속성이 있을 수 있다는 것이고, 이러한 종속성은 상관관계에 나타나지 않습니다. 예를 들어, 두 변수가 있고, 이 두 변수의 모든 점들이 어떤 나선형으로 정렬되어 있다면, 이 두 변수 사이에는 매우 강한 종속성이 있죠? 하지만 실제로 이 두 변수 사이의 상관관계를 계산하면 상관관계가 없습니다. 이 경우에는 이 두 변수의 정보 내용이 실제로 아주 작습니다. 나선형에서의 위치만 나타내는 양입니다. 그들은 상관관계가 없으므로 두 변수에서 많은 정보가 나오는 것처럼 보일 수 있지만 실제로는 그렇지 않습니다. 하나의 변수를 다른 변수로부터 예측할 수 있습니다. 이것은 우리가 정보 내용을 측정하는 매우 근사적인 방법만 가지고 있다는 것을 보여줍니다.
ENBLE: 그래서 지금 이것에 대해 작업 중인 것 중 하나인가요? 정보 내용을 최대화하고 최소화하는 지 어떻게 알 수 있는 큰 질문인가요?
YL: 또는 우리가 이를 위해 사용하는 대리자가 우리가 원하는 작업에 충분히 좋은지 여부에 대한 문제입니다. 실제로 기계 학습에서 우리는 항상 최소화하려는 비용 함수를 사용하지 않습니다. 예를 들어, 분류를 수행하려고 합니다. 좋아요? 분류기를 훈련시킬 때 최소화하려는 비용 함수는 분류기의 오류 수입니다. 하지만 그것은 미분 가능하지 않고, 심각한 비용 함수이기 때문에 최소화할 수 없습니다. 신경망의 가중치를 변경해도 오류가 발생하지 않기 때문입니다. 그리고 오류가 발생하면 오류가 긍정적인지 부정적인지에 따라 오류가 크게 변경됩니다.
ENBLE: 그래서 당신은 확실히 그레이디언트를 흐르게 할 수 있는 목적함수인 프록시를 가지고 있습니다.
YL: 맞아요. 사람들은 이 교차 엔트로피 손실 또는 소프트맥스를 사용합니다. 이름은 여러 개 있지만, 같은 것입니다. 기본적으로 시스템이 범주 각각에 대해 제공하는 점수를 고려하여 시스템이 하는 오류의 수를 부드럽게 근사화한 것입니다.
ENBLE: 다루지 않은 내용 중에 다루고 싶은 것이 있나요?
YL: 아마도 주요한 포인트를 강조하는 것이 좋을 것 같아요. AI 시스템은 추론할 수 있어야 하며, 이를 위해 제안하는 과정은 어떤 잠재 변수에 대한 목적함수를 최소화하는 것입니다. 이를 통해 시스템이 계획하고 추론할 수 있습니다. 우리는 확률적인 프레임워크를 포기해야 한다고 생각합니다. 왜냐하면 고차원 연속 변수들 간의 의존성을 포착하려고 할 때 추론이 어려워지기 때문입니다. 그리고 생성 모델을 포기해야 한다고 주장하고 있습니다. 왜냐하면 시스템은 예측하기 너무 어려운 것들을 예측하는 데 너무 많은 자원을 할애해야 하기 때문입니다. 그리고 이것이 대부분입니다. 이것이 주요한 메시지입니다, 원하신다면요. 그리고 전체적인 아키텍처. 그리고 의식의 본질과 구성자의 역할에 대한 가설들이 있지만, 이것은 실제로 추측입니다.
ENBLE: 다음에 그것에 대해 이야기하겠습니다. 제가 물어보려고 했던 것은, 이걸 어떻게 벤치마크하나요? 하지만 아마 지금은 벤치마킹에서 조금 더 멀리 떨어져 있을 것 같네요?
YL: 그렇지 않아요. 어느 정도 단순화된 버전에서는 가능합니다. 제어나 강화학습에서 모두 하는 것처럼, 불확실성이 있는 아타리 게임이나 다른 게임을 훈련시키는 것입니다.
ENBLE: 시간 내어 주셔서 감사합니다, Yann.